Web tracking via HTTP cache cross-site leaks
September 8, 2019tl;dr
Google Chrome and Mozilla Firefox desktop users using the default configuration can be identified and tracked online if they are logged-in popular social networks, have JavaScript enabled and visit malicious websites.
introduction
During the beginning of the year I have been reading about some Cross-Site leak (XS-leak) techniques which can be used to disclose reserved information about a victim surfing a malicious website, such as books they’ve read or people they chatted with. While the first (?) cross-site leak techniques were introduced back in 2000 (!), they regained popularity lately thanks to web browsers’ evolution. A more detailed explanation of the specific browser features one can abuse nowadays are available on the xsleaks repository.
In the last months I have tried to find a new attack vector, which is going to be explained here; keep in mind that the underlying "technique" is known (thanks for sharing @sirdarckcat!) and since browsers vendors are kind of fixing it, that’s why many popular websites chose not to fix the leak on their end but instead ascribe the responsibility to web-browsers – more about this in #is-my-browser-affected.
table of contents
- old HTTP cache management
- common web app traits, scenarios and bypasses
- example of a vulnerable app
- how exactly can we tell a user from another?
- what about load-balancers and CDNs?
- demo with proof-of-concept exploit
- case study
- related work
- is my browser affected?
0. old HTTP cache management
Web browsers used to manage caching mainly on its expiration, without considering origins or cross-site permissions. Because of that, the cache storage between a vulnerable web app and a malicious website wasn't segregated: for example, if the same image is requested on three different websites the browser loads the image once and then loads it from cache the next two times (in case the image provider doesn’t send anti-cache instructions, which are rare for pictures). #is-my-browser-affected explains the current state of adoption of the double-keyed cache mechanism (that is, origin-linked cache storage), which would prevent this attack, but for now let’s just know that latest default Mozilla Firefox and Google Chrome are (still) affected as of this writing.
1. common web app traits, scenario and bypasses
A lot of the most popular social networks nowadays share many common traits, like who are you connected to, what are your interests or how does your public profile look like.
While we can generalize this technique to fit many particular contexts, I chose to focus on one of the most common features: web apps where users can upload a personal profile picture and make it public (or not) via their profile page.
The specific image URL of such picture is many times the same, whether you are logged-in with an identity, another one or not logged-in.
This detail allows to identify a victim out of a group of potential targets and in particular websites to discover social connections, relationships and other personal information which they doesn’t want to share publicly.
(A similar attack involving images is Leaky Images: Targeted Privacy Attacks in the Web, jmp #related-work for a detailed comparison).
That being said, there are some caveats of this specific attack vector:
- the victim must have a custom profile picture
- the victim must have JavaScript enabled and use a vulnerable browser (see #is-my-browser-affected)
- the resource location (image URL) must be shared between the victim and the attacker
- the web app must have a specific page where just its (or just the target group) picture is included, for example the settings or the message list pages which typically include the profile picture and the profile picture of other users, respectively
- the image cache must be cross-site shared, as in the cache entry must be available both to the vulnerable website and the attacker website
- the image cache expiration must be sufficient for the attack to be accomplished
1.1 example of a vulnerable app
Let’s make an example of a vulnerable web application where an attacker controls (at least) two different identities, john and julia:
- their own profile image is displayed at
/settingsand others’ at/[username] - image resources are cached for some time, for example 30 minutes
It is possible to check if the web app is affected through the following steps:
johnnavigates tojulia's profile and notes their image URL – even multiple ones in case there are different sizes shown (e.g. 320x320, 320x480, etc), for examplehttps://vulnerable.app/320x480/julia.pngjuliavisits their own settings page (or any reserved page which includes their own profile image, even in a different size) notes their own profile image location(s) for example:https://vulnerable.app/320x320/julia.png- In case the URLs match (just the size differs but that depends on the specific page seen), the web app doesn’t differentiate between users (as in doesn’t use per-user secret URLs), which is useful for caching, but at the same time allows this attack to work
- If such pictures are cached, which very rarely doesn’t happen, and the web app allows the browser to re-use such cache (just check the headers), then the attacker is able to track anyone who uses the platform.
1.2 how exactly can we tell a user from another?
By applying a trick from xsleaks’s repository, JavaScript allows us to turn the client browser into a side-channel and exploit those website traits I’ve just explained:
- Force HTTP cache flush for each image URL of our targets, for example by making the server return an error through a malformed referer header via History API
- Load the leaking endpoint via iframe, pre-render or new window. Note this needs to be done just one time since it is the same page for everyone most of the times, e.g.
/settings - Force HTTP cache use for each image, again for example by making the server return an error. During this step only the cached image will successfully load
- Correlate the image(s) which gets loaded to the target username, if none the target is not logged-in or not in the victims group. (The two states can again be distinguished with the same technique but then it’s not really relevant)
Here’s a drawing which visually explains the various steps, note the victim group is composed of tim, alice and tom:
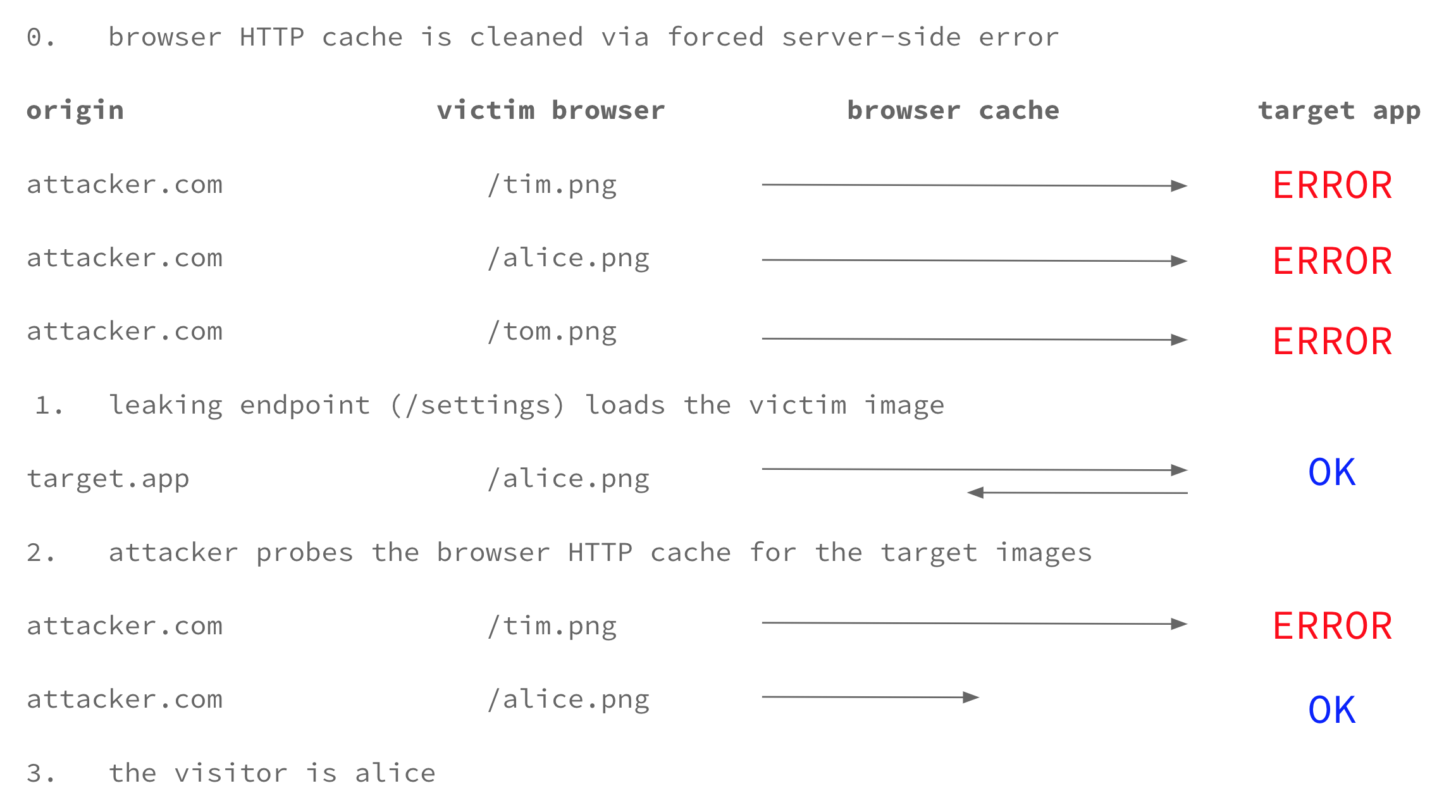 *Note that while I call "Origin" the origin of the specific HTTP request, that HTTP header is not sent in CORS image requests, turning simple remediations like setting
*Note that while I call "Origin" the origin of the specific HTTP request, that HTTP header is not sent in CORS image requests, turning simple remediations like setting Vary: Origin in the response headers useless.
Interestingly, not using a custom profile picture is a simple remediation to this technique since the web app would fallback on a default image and thus make it difficult for the attacker to find the victim in all the users without a custom picture.
1.3 what about load-balancers and CDNs?
Websites use different URLs to provide the media resources, but even though the location is basically the same (many times only the subdomain changes), that complicates the situation because an attacker needs to clean and then probe the cache for all the endpoints the victim could have used. It’s not a deal-breaker though, the attack just gets longer to finish in terms of time.
That’s another story for CDN endpoints (edges) whereas it’s not possible to predict which one is going to be used by the victim, for at least two reasons:
- that depends on their physical position, which an attacker doesn’t have/care
- the URL is edge-bound: the path changes depending on the origin used and it’s not predictable (we can’t dinamically forge the signature)
There are bypasses for those limitations too, but they are neither elegant nor fast.
Since an attacker just needs to get all the possible URLs for a picture anywhere in the world, they could use a bunch of HTTP proxies physically located near all the CDN edges to extract the relative image(s) endpoints, then repeat for every victim and create a map of all the victims' images.
Another idea could be to use the victim browser to discover the CDN edge(s) they are going to use and just test them automatically.
1.4 demo with proof-of-concept exploit
The exploit code is based on the xsleaks cache-referrer example, head to the demo to try it out.
2. case study
I reported this vulnerability to many websites, the majority of them replied with something along the lines of "it’s a web browser problem and they are fixing this", which is an understandable reply, but doesn’t really protects end users until the browser vendor does decide to implement the double-keyed cache mechanism; an alternative could be to start using secret per-user URLs (like facebook does), but that'd a big change, another could be to stop caching such images, but that'd be pretty dumb in many cases – it’s not an easy decision to make for which I don't think there is the right answer, it just depends on the specific web app context.
That being said, the case study I chose is still fixing this (yes, 90 days have already passed), so I will update this section with the actual case study once they fix it or it is no more exploitable.
However,I am sure you can find a vulnerable real-world example yourself without having me point to one, most probably even a social network you use, just by following the steps at #example-of-a-vulnerable-app, potentially #what-about-load-balancers-and-CDNs and #demo-with-poc-exploit.
3. related work
Since april 28, date of the first report submitted about this vulnerability, I have been on the lookout for similar researches; the most similar is "Leaky Images: Targeted Privacy Attacks in the Web", which has been recently presented. Both techniques rely on images and aim at precisely identifiying the victim(s) with a 100% success rate, so here’s a detailed comparison which should clarify the differences:
| this one | Leaky Images: Targeted Privacy Attacks in the Web | |
|---|---|---|
| what does the attacker need to know about the victim? | profile image URL / username | username / email |
| how does the victim interact with the attacker? | visits a malicious website |
|
| does it reside in a browser or web app bug? | both | web app |
| what are the web app requirements? |
|
|
| what are the browser requirements? |
|
none |
4. is my browser affected?
As we have seen it depends on the web app, but also on the user web browser; here's a recap from @sirdarckcat’s blog post which is still valid:
- The attack is “complicated” for Safari users, the reason is because Safari has this thing called “Verified Partitioned Cache”, which is a technique for preventing user tracking, but that also accidentally helps with this. The way it works is by keying the cache entries to their origin and to the site that loaded the resource. The attack is still possible (because the caching behavior is based on heuristics), but the details of this are probably worth a different blog post.
- Chrome will hopefully not be vulnerable anymore - the reason is because Chrome is experimenting with “Split Disk Cache”, which is somewhat different from Safari’s, but has the side-effect of protecting against this attack. Note that this feature is currently behind a flag in Chrome (–enable-features=SplitCacheByTopFrameOrigin), so test it out and send feedback to Chrome =).
- Firefox users are vulnerable, but they have a preference they can enable to get similar behavior - this is called “First Party Isolation”, and is available as an add-on and as a pref (privacy.firstparty.isolate=true). It takes a similar approach to the one implemented in Chrome a few steps further, and splits not only cache but several other things (such as permissions!), so test it out too, and send feedback to Firefox.
- Tor browser users are protected by default since pref “privacy.firstparty.isolate” is set to true.
updates
- september 10: today Google is going to release Chrome 77 which will break the exploit in use, however since the safe cache mechanism isn't there yet it is possible to use other means for cache eviction (thanks for the heads up @lbherrera_!) -- I'll update the poc in the next days
learn more
- "Timing Attacks on Web Privacy": http://sip.cs.princeton.edu/pub/webtiming.pdf
- XS-Leaks repository: https://github.com/xsleaks/xsleaks
- "Leaky Images: Targeted Privacy Attacks in the Web": https://www.usenix.org/system/files/sec19-staicu.pdf
- "XS-Search abusing the Chrome XSS Auditor - filemanager 35c3ctf": https://www.youtube.com/watch?v=HcrQy0C-hEA
- "Timing Attacks Have Never Been So Practical: Advanced Cross-Site Search Attacks": https://www.youtube.com/watch?v=vzp7JdezZRU